Every TSDB have to deal with vast data volumes. But it’s not only writes per second. There is a different dimension to the problem which is not tackled by most TSDB vendors. This problem is a dataset cardinality, the number of individual series in the database. It plays a really huge role.
It’s safe to assume that any TSDB will work reasonably well if the cardinality is small (100K of metrics). But when cardinality is high (millions of metrics) we have to deal with the hard problem. Most TSDBs will start to generate write timeout errors or eat up the RAM. For instance, Akumuli will use a lot of RAM because it allocates some memory for every time-series stored on disk.
Akumuli’s memory requirements depend on cardinality. To handle 1M unique time-series it needs around 10GB of RAM. 2M unique time-series will need 20GB and so on.
Where did this numbers came from? First of all, Akumuli writes data in fixed-size blocks. Each block is 4KB. When you create a time-series and write data into it, Akumuli allocates a memory block and fills it with compressed data. When it gets full it writes it to disk and allocates the next one. It have to write in 4KB blocks to minimize wear leveling and write amplification of the SSD. It will always allocate 4KB of memory for every time-series for this purpose. Even if only small fraction of this memory is used. So, the memory y expenses for all series will be cardinality * 4KB. If the database stores one million series the memory resident pages will eat around 3.8GB of RAM.
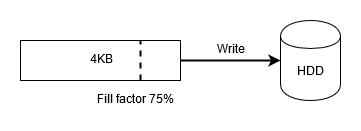
This problem was greatly reduced in latest release. New algorithm allocates 4KB pages partially by 1KB chunks! When you start writing it allocates first 1KB chunk (so almost empty block will use only 1KB of RAM, not 4KB). When the first chunk gets full it allocates the second one and so on, until all four chunks (4KB) will be allocated and filled with data. Now it’s time to write it to disk.
The problem is that we have four disjoint 1KB memory chunks that we need to write into one 4KB page on disk. We can’t just perform four 1KB writes because they won’t be atomic. If something will happen in the middle we will end up with partially updated block in the database! The database will be corrupted. Also, multiple updates are bad for SSDs. SSD can’t update pages in-place. It’s controller uses read-update-modify protocol to fetch old page, update it and write it to the new place. If we will write data this way it increase the wear leveling and will introduce a lot of work for the garbage collector inside the SSD controller.
So, we need to write this four 1KB chunks as one 4KB block. We can actually do this using the vector I/O (aka scatter/gather I/O). Using one writev call on Linux we can pack all four chunks into one iovec array which will be written atomically. Using only one write operation. This method is as efficient as ordinary write operation given that it involves only one syscall. But the most important, it provides atomicity so there is no in-between state. The page will be written completely or not written at all.
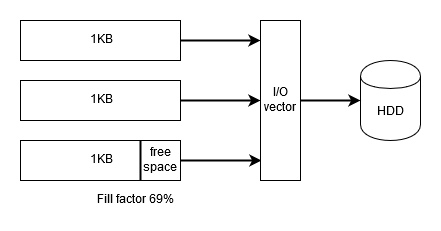
This simple trick allows to lower memory requirements by 50%. This is due to the fact that on average every series will have just two 1KB chunks allocated. I’m not going to bore you but it’s easy to prove if you curious.
This trick is already used by recent version of Akumuli but it’s not the entire solution. I’ll write about different memory optimizations later.