Tag support is very important for any modern time-series database. The world from which time-series data is coming is complex. Time-series data is not just a time-ordered values (measurements), this time ordered values form individual series and different series can relate to each other in numerous ways. The simplest example is an object that produces many measurements of different types. E.g. the server can have hundreds of different metrics like “CPU User”, “CPU System”, but more interestingly, it can have series names like “Number of software interrupts/sec of type X on core=Y” metric.
The particular series may look like this: proc.softirqs host=dev cpu=0 type=SCHED. The type tag may have tens of possible values as well as the cpu tag. This can be expressed using hierarchical naming scheme of Graphite in several ways, e.g. proc.softirqs.dev.0.SCHED or proc.softirqs.dev.SCHED.0 but here is the problem, the database user should know what each level of the name means! The hierarchical naming scheme is not self-descriptive. There should be a schema somewhere, it should be available to both readers and writers and it’s not stored in the database! So each agent on every machine should use proc.softirqs.dev.0.SCHED and not proc.softirqs.dev.SCHED.0 otherwise, you’re doomed. And when you see this proc.softirqs.dev.0.SCHED name you may only guess what this bloody ‘0’ means.
The most critical problem is that this schema enforces hierarchy even when there is no hierarchy at all. In our example, both type and cpu names are equally important.
In Akumuli the tags are supported from the start. There is no fields or tables since everything can be modeled using tags. Tags not only can but should be redundant. There is a hard limit on series name length thought (4KB). Akumuli uses some modern techniques to enable this multi-dimensional queries and joins using tags. I’ll try to explain them in this article.
Forward Search
At the beginning, there was no index at all. Akumuli had been storing all series names in RAM in the string pool. There was a hash table that mapped ids to offsets inside the string pool, and the other hash table that mapped offsets to ids. New names were simply added to the string pool. Each series name was converted to the canonical form. In the canonical form, all unnecessary whitespace characters were removed and tags were sorted alphabetically.
To query this data structure regular expressions were used. Since all series names were stored contiguously it was possible to search the entire set of names using one regex search. This is quite dumb but it worked really well and it was quite fast. Regular expression libraries are fast and you can search through hundreds of megabytes of text in milliseconds. In IR this is called a forward search. Normal search engines used to deal with large text documents so forward search is not an option but time-series names are short so, one can use forward search with acceptable results even in interactive applications.
Inverted Index
However, some time ago I started to work on Grafana data source plugin. This plugin needed an autocomplete functionality from the database. The autocomplete is implemented using three queries:
- suggest metric names by prefix (proc.cpu.???);
- suggest tag name by tag prefix and metric name (proc.cpu.user hos???);
- suggest tag value by value prefix, tag name, and metric name (proc.cpu.user host=dev-???);
It turned out that it’s problematic to implement this queries using regular expressions so I decided to implement an inverted index. In normal search engines, inverted index maps words to documents so all documents containing particular word combinations can be found without scanning each and every one of them. In Akumuli I’m using tag=value pairs instead of words and series names instead of documents. Check this example:
Let’s say that the data inside the index looks like this:
| Id | Series Name |
|---|---|
| 0 | proc.softirqs host=dev cpu=0 type=SCHED |
| 1 | proc.softirqs host=dev cpu=1 type=SCHED |
| 2 | proc.softirqs host=dev cpu=0 type=TIMER |
| 3 | proc.softirqs host=dev cpu=1 type=TIMER |
| 4 | proc.softirqs host=test cpu=0 type=SCHED |
| 5 | proc.softirqs host=test cpu=1 type=SCHED |
| 6 | proc.softirqs host=test cpu=2 type=SCHED |
| 7 | proc.softirqs host=test cpu=3 type=SCHED |
| 8 | proc.softirqs host=test cpu=0 type=TIMER |
| 9 | proc.softirqs host=test cpu=1 type=TIMER |
| A | proc.softirqs host=test cpu=2 type=TIMER |
| B | proc.softirqs host=test cpu=3 type=TIMER |
In this case these posting lists will be built:
| Tag-Value pair | Posting list |
|---|---|
| host=dev | 0, 1 |
| host=test | 3, 4, 5, 6, 7, 8, 9, A, B |
| cpu=0 | 0, 2, 4, 8 |
| cpu=1 | 1, 3, 5, 9 |
| cpu=2 | 6, A |
| cpu=3 | 7, B |
| type=SCHED | 0, 1, 4, 5, 6, 7 |
| type=TIMER | 2, 3, 8, 9, A, B |
So, suppose we need to find all the metrics from host ‘test’ that has a ‘SCHED’ type. We should read ‘host=test’ and ‘type=SCHED’ posting lists and find the intersection:
| Tag-Value pair | Posting list |
|---|---|
| host=test | 3, 4, 5, 6, 7, 8, 9, A, B |
| type=SCHED | 0, 1, 4, 5, 6, 7 |
Query result is 4, 5, 6, 7:
| Id | Series Name |
|---|---|
| 4 | proc.softirqs host=test cpu=0 type=SCHED |
| 5 | proc.softirqs host=test cpu=1 type=SCHED |
| 6 | proc.softirqs host=test cpu=2 type=SCHED |
| 7 | proc.softirqs host=test cpu=3 type=SCHED |
That’s some basic IR stuff.
Optimizations
The main problem that I encountered was a high memory usage. Each series has a dozen of tags. Each tag-value pair has an associated postings list (an array that contains id’s of all series that contains this tag-value pair) so a value should be added to a dozen of posting lists. The value is 64-bit wide and a cardinality can be huge so these posting lists grow big. Apart from posting lists, I used series names as keys in a hash table that been used to map them to ids.
The first problem was solved by compressing posting lists in memory. Each posting list is just a sorted array of 64-bit integers. I started to build positing lists using delta encoding combined with LEB-128 and get 4x improvement as a result.
The second problem was solved using a string pool. I started to use the pointer to the value inside the string pool as a hash table key.
High Cardinality
The most complex problem that I have only appeared with high-cardinality data sets. There is quite a lot of unique tag-value pairs inside high-cardinality data sets. As result, a lot of small posting lists should be created. Compression won’t be effective in this situation (since every posting list will contain small number of ids) and memory fragmentation will become a problem.
This problem was solved using Count-Min Sketch. The normal CM-sketch used to count events. It consists of several arrays of counters. When the new event arrives, we should calculate N different hash values (N is a number of arrays we have), locate N counters, and increment them. To estimate the count for the event we should do almost the same - calculate the hashes, locate the counters but instead of incrementing them we should get the smallest one. This guarantees that hash collisions will affect the result the least.
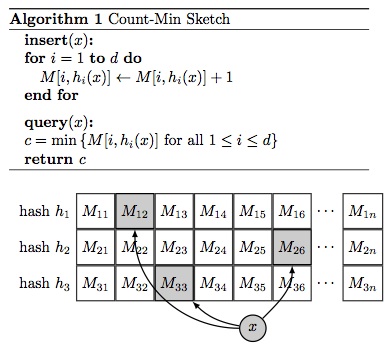
In Akumuli’s index, the counters were replaced by the posting lists. When new series shows up, we need to compute N=3 hashes, locate 3 posting list, and add the new element to every one of them. As result, each posting list will have values from many tag-value pairs, not just one. To read the posting list we should do the same trick. Calculate 3 hashes, read 3 posting list, and then find the intersection between all of them. In a case of hash collision, the id of the series will end up in one posting lists out of three (way less likely in two or all of them). To eliminate the collisions further we should check that every series name that we’ve found contains the tag-value pair that we need using simple substring search.
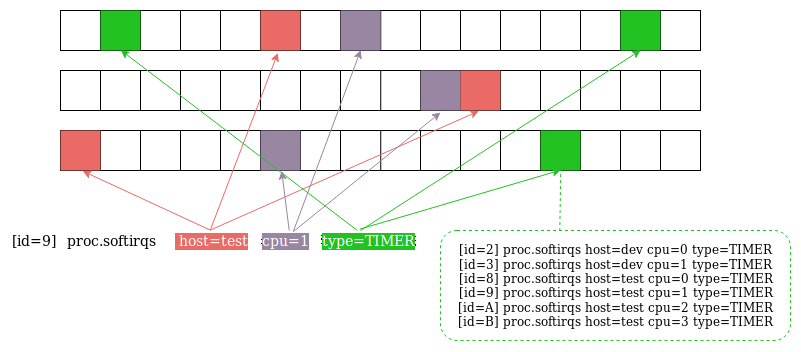
This trick saves the day when we have a high cardinality set of tags. In case of Akumuli, the size of the table is fixed so there is no unneeded allocations and fragmentation. This inverted index can store really high number of series names and query it very efficiently.