Akumuli was designed with performance in mind from the very beginning. I set the lower bound for the write throughput at the 1M writes/second level as one of the project goals. Every version so far delivers this performance, that’s why this number is mentioned on the project page. But this is only a lower bound. It would be interesting to see what level of performance is achievable with today’s hardware!
To answer this question I tested Akumuli on AWS and it managed to sustain 4.5 million write operations per second on a dedicated m3.2xlarge node. This isn’t a peak but steady write throughput over the network. And my tests showed that it scales almost linearly on a multicore machine.
Methodology
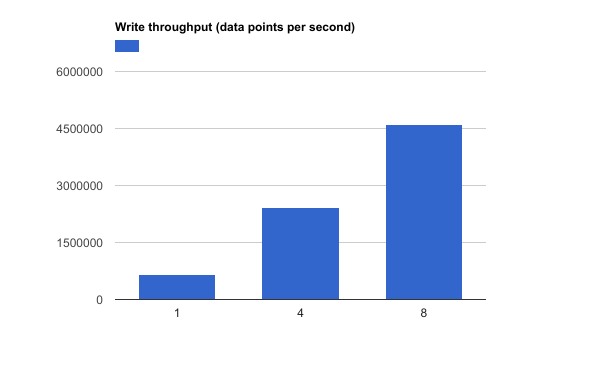
Akumuli has a configuration option called TCP.pool_size. It controls the server side parallelism. By default, this option is set to one. But it can be increased on multicore machine. I ran the benchmark with different TCP.pool_size values on the eight core machine and here are the results:
| Number of threads | Throughput datapoints/sec |
|---|---|
| 1 | 693 984 |
| 4 | 2 433 831 |
| 8 | 4 547 421 |
The input was constructed using this script. All test data was generated beforehand and was divided into eight independent archives (each archive had its own set of time-series). Each archive contained exactly 86401000 data elements. All eight archives had around 691M data elements (3.5G compressed).
I started Akumuli with different TCP.pool_size values and measured the time it took to write all the data. After each run, the resulting database size was 2.7GB (4.2 bytes per element).
Single m3.xlarge instance was used to generate load. I had been using 8 writer processes working in parallel each process transmitting its own set of series to feed the data to akumulid daemon.
What makes Akumuli so fast?
Storage in Akumuli is based on append-only B+tree. Each series is represented using a separate B+tree instance and can be modified independently. All B+trees reside in the same file.
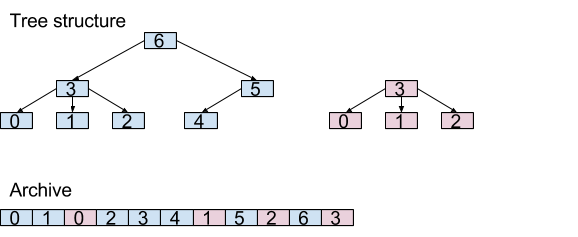
Code in write-path is based on the observation that different TCP-sessions usually write data to the different time-series. When session writes something to the series first time the corresponding B+tree that stores series data get assigned to that session. After that, the session will be able to write data to this B+tree without any synchronization. If B+tree is already owned by another thread, additional synchronization with the owner thread will be needed.
Final notes
Using a single-node instance of Akumuli running on the m3.2xlarge instance I managed to write 4.5M data points / second. This is not a high-end machine by any means. I’m looking forward to running this test on more performant hardware and see the results. That would be very interesting to try.