In the previous article, I wrote about the reasons that made me choose B+tree based data-structure for Akumuli. In this article, I want to tell about another advantage of the B+tree based design compared to LSM-tree.
A shallow introduction into the LSM-tree algorithm
LSM-tree was designed for the world where the sequential read and write throughput was relatively high and the random read and write throughput was relatively low. In a nutshell, it trades increased I/O bandwidth use for reduced random I/O. LSM-tree is composed of several components (C0, C1, …, CK). The C0 component is usually kept in memory, new records are added to the C0 component until it gets full. When this happens the C0 component can be sorted by key and written to disk into C1 component. The C1 components can be merged into C2 components and so on. All this operations are sequential.
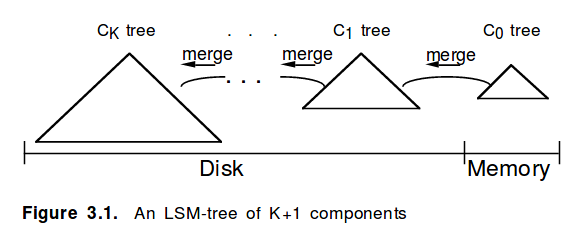
(source: http://www.cs.umb.edu/~poneil/lsmtree.pdf)
To read the data we may need to scan a range of keys inside the C0, C1, …CK components and merge the results. Each scan is a sequential read operation. To locate the begining of the range inside each component we can use binary search because each storage component is sorted by key.
The Problem
What’s the problem here, one may ask. The problem is that we need to read old data to be able to write the new! The same data gets written to disk many times during every merge. The key spaces of different storage components can overlap, thus we need to actually read the data and perform the 2-way merge and write the result! E.g. it’s quite possible that we may need to read much more than 1GB from disk (the existing storage component and the new one) to add 1GB of data to the database. In addition to this, we may need to run compaction procedure from time to time.
The typical TSDB workload looks like this, the writers are always active and the write rate is about the same (and quite high) all the time, but the readers are also active. It’s quite possible that the TSDB should send data to Grafana, and BI tools, and some background batch jobs, all at the same time. The database built on top on top of LSM-tree often needs to perform large sequential scans to read the required data. This processes can consume all read throughput of the storage device!
But the lack of the read bandwidth can stop merge and compaction procedures from keeping up with the writing process. Because we need to read data during the merge and during the compaction the writing process can be quite slow if the readers are too active. If compaction is not keeping up with writes, we may run out of disk space. If merge process is not fast enough, we may run out of file descriptors. The other possible problem is that the reads and the startup time can become slower if the merge is not keeping up because we’ll need to read from many unmerged files.
Another incarnation of the problem is ZFS compaction. Some time-series databases are relying on ZFS for compression. They write uncompressed data to disk in a format that can be easily compressed by the general purpose compression algorithms threefold. At some point, the ZFS will kick in and compress this data down to several bytes per data point but before that each data point will use 16 or even 24 bytes. I never saw this behavior in real life but I suspect that it’s quite possible that ZFS compression can be unable to keep up with the write rate if the readers are too active. In this case, we may also run out of disk space pretty soon.
Is there anything we can do about it?
Let’s see how Akumuli improves this situation. First and foremost, Akumuli doesn’t need to read anything to be able to write new data. Well, it needs to read old data if you want to insert something or update or delete (and these operations is not fully implemented yet) but if you’re adding new data with increasing timestamps there will be no reads at all.
Another property that greatly reduces the hassle between readers and writers is that all I/O is aligned. If you’re appending new data to a file unaligned, the system will read old data first. As result, the read throughput will be wasted even if your algorithm doesn’t need to read anything at all. I can recommend this fantastic paper if you want to dig deeper into the problem of the unaligned writes.
In the past the seek time of the hard drives was the main limiting factor but today the limiting factor is a bandwidth of the storage device. Modern SSD and NVMe drives may have very small latency and great random I/O throughput but the bandwidth is still limited. Because of this, the old optimization strategies (linearize all the things!) is not that effective anymore. Being able to read and write data only sequentially doesn’t hurt at all but the ability to read and write data precisely is more important because it saves the I/O bandwidth. Also, it worth to mention that this design makes the database prepared for the next gen byte-addressable non-volatile memory.
No free lunch
There are downsides of cause. There is a RUM conjecture that states that we can’t build the system that doesn’t have any read overhead, no update overhead, and no memory overhead at the same time. Akumuli sacrifices memory overhead to have great read and write performance. It needs to store some information in memory to enable this “blind” writes. As a result, the memory footprint grows with the cardinality of the data set (number of metrics). Just to be honest, you may need up to 16GB of RAM to work with 1M unique time-series, 32GB for 2M and so on. I’m planning to add an ability to disable “blind” writes to support higher cardinalities and limit memory use in the future. But this will come at the expense of decreased write throughput. This is a trade off to think about.