Recently I tested Akumulil on the m3.2xlarge EC2 instance. Write throughput was around 4.5 million elements/second. This number might look unrealistic at first but in fact, that’s less than 20MB/s of disk write throughput because each data point is tiny (less than five bytes in that particular case) and all data is compressed in real time.
Next step was to try it on a bigger machine. I chose c3.8xlarge EC2 instance with 32-core Intel Xeon E5-2680 v2 and SSD. This is what I did:
- I created test data beforehand (32 gzip archives, 16GB compressed) and uploaded it to S3.
- Then I created 4 m3.xlarge EC2 instances to generate load.
- From each m3.xlarge instance, I downloaded the test data.
- Then I started a single c3.8xlarge instance, build and installed Akumuli, set
TCP.pool_sizeparameter to 32, created the database and started the network daemon. - After that I downloaded and edited the
run.shscript on each m3.xlarge box. I setTARGET_HOSTvariable correctly and decreased the number of archives from 32 to 8 (each host had been sending the unique subset of test data). - Then I started
run.shon all machines simultaneously usingparallel-ssh.
During the test run, each m3.xlarge instance had been sending data in parallel using 8 threads (32 threads total). All this data was written to disk in parallel on the c3.8xlarge instance. This is how everything looked in htop:
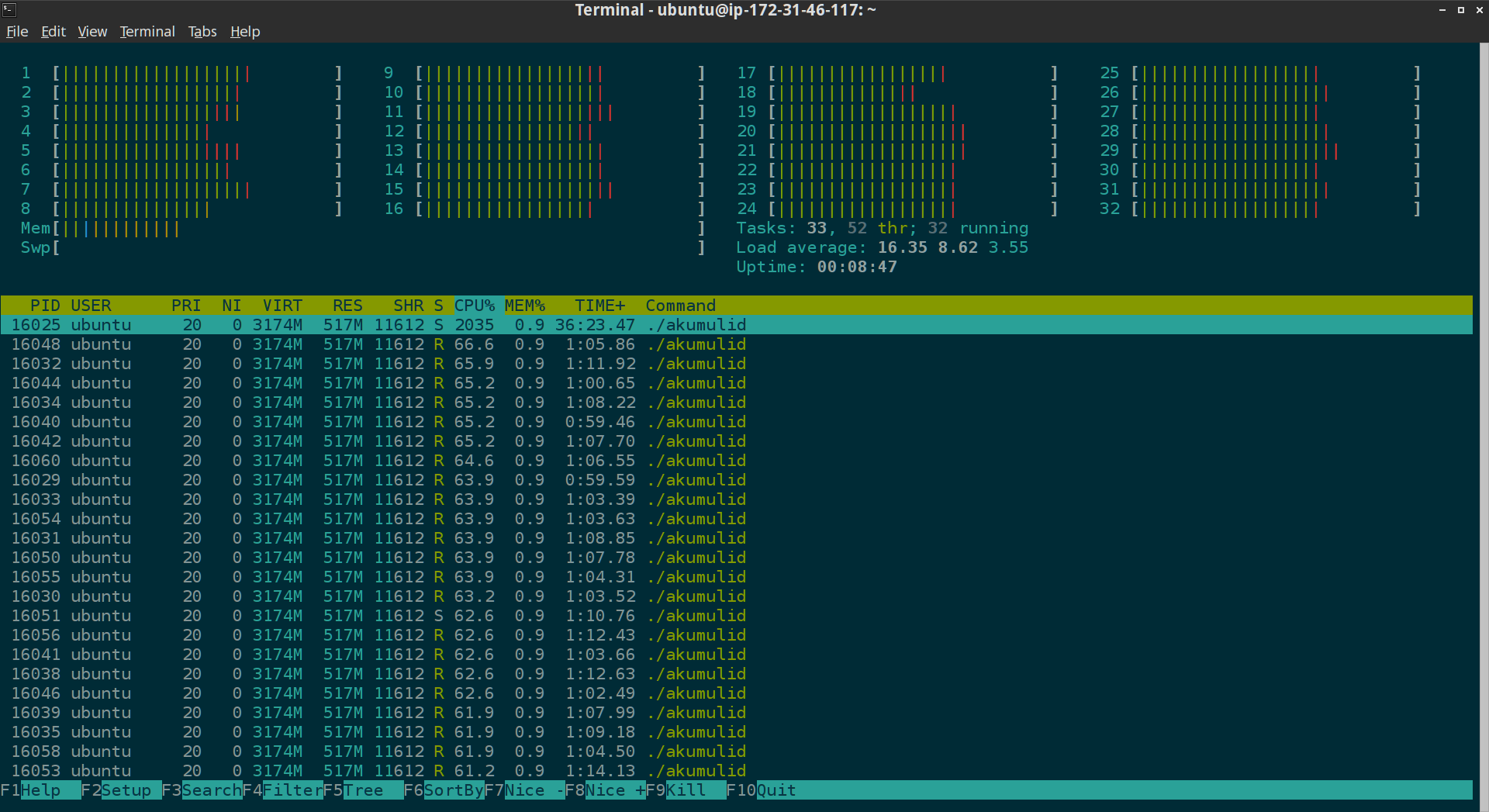
The dataset contained 2764832000 data points in 32000 series. All nodes finished sending data in less than 3 minutes and write throughput was above 16 million elements/second. Resulting database size was 11GB. SSD drive was underutilized, it can write far more than 64MB/s that was demanded by this test run.
This puts Akumuli in the same ballpark as BTrDB. As far as I know, these are the only two open source time-series databases that can write data in parallel. All other solutions still struggle with single writer solutions.